

🔍 Decoding vector databases: Exclusive insights & free training inside!
Vector databases 101 delivered straight to your inbox...

Ah, vector databases! Surely you’ve heard of them.
Today I want to share a little nugget from within my research treasure trove.
Not too long ago, over on Twitter I stumbled upon the growing buzz around vector databases.
Why the excitement, you ask?
Well, let me explain…
Vector databases are a fundamental component of generative AI infrastructure. With the massive generative AI explosion we’ve seen this year, the need for vector databases has also taken off at breakneck speed.

But, what is a vector database exactly?
Simply put, a vector database is a database management system designed to efficiently store, manage, and retrieve multidimensional data, often used for similarity searches in machine learning and generative AI applications.
While traditional relational databases store, manage, and retrieve data from structured tables and defined columns, vector databases think a bit outside that box.
Their vectorized data format (aka; “vectors”) is especially handy when dealing with large-scale and multifaceted datasets.
I’ll borrow this handy-dandy diagram from Jatin Solanski to illustrate:
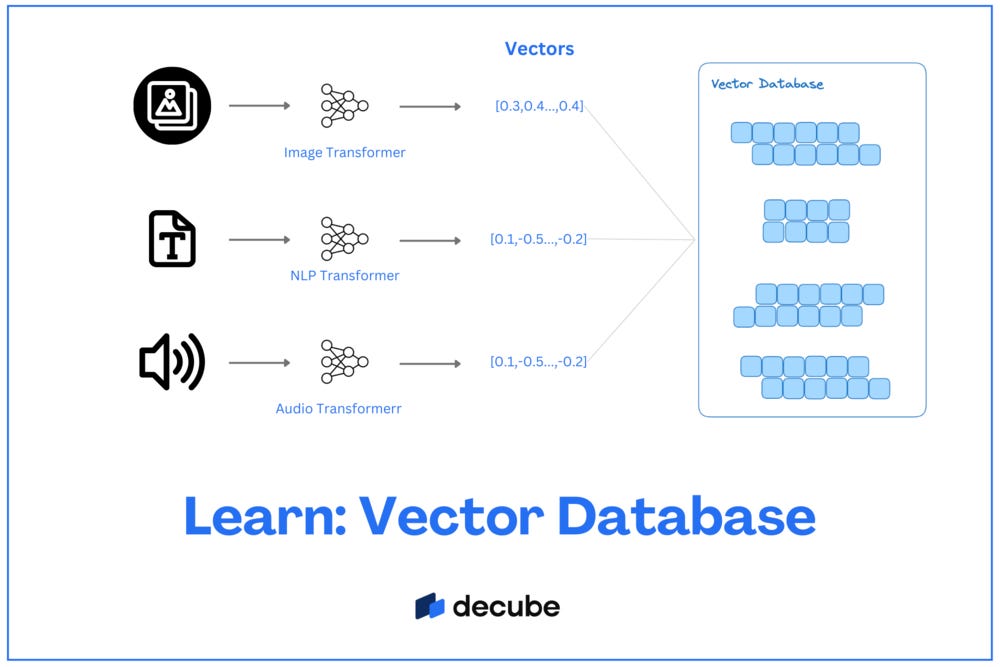
What’s this got to do with the price of tea in China?
With generative AI breaking the forefront of every single aspect of business and digital work, technologies that directly support generative AI are of course getting their day in the sun. Case in point, vector databases.
With respect to large language models (LLMs), vector databases are significant because they allow for efficient storage and retrieval of high-dimensional data. They enable quick similarity searches while also enhancing the model's ability to reference vast amounts of information. In this way, vector databases improve the response accuracy and context understanding of LLMs.

Source: Pinecone
Here are some of the ways that vector databases are helpful when working with LLMs:
Encoding information: LLMs can produce feature vectors, which are compact representations of longer text inputs or other data types. Vector databases store these feature vectors.
Efficient similarity searches: When a new query comes in, an LLM generates a corresponding vector for it. The vector database can then quickly identify "nearest neighbors" or vectors that are most similar to the query vector. This is much more efficient than scanning through raw data.
Scalability: As the amount of data and knowledge grows, it becomes impractical to directly search raw data every time. Vector databases allow LLMs to scale by providing a means by which to efficiently search through vast amounts of data using compact vector representations.
Handling contextual information: Vector representations capture semantic meaning and context. When searching for relevant information, vector databases can identify vectors (and thus data points) that not only match the direct query but also align with the contextual or semantic intent behind it.
At the most basic level you could say that vector databases act as bridges that allow LLMs to tap into vast reservoirs of data in an optimized manner, thus ensuring rapid and contextually accurate responses.
Now that you understand what vector databases are and why they’ve become so important so fast, I wanted to let you in on a free live training where you can go to learn late-breaking facts on the use of vector databases across industry.
📆 Free Live Training: The Current State of Vector Databases
On Wednesday September 27 at 10 am PDT, you’ll get the chance to join a free live training session with Sanjeev Mohan, a former VP at Gartner. In just 60-minutes, he’ll decipher the intricate world of vector databases and offer deep technical insights that are custom-tailored for engineering leaders (and aspiring leaders)

What You’ll Get:
👉 Technical training on vector embeddings and the pivotal role they play in modern AI architectures.
👉 Key design considerations in constructing efficient AI pipelines and integrating vector search capabilities.
👉 Best practices in evaluating and selecting vector-enabled databases for scalable applications.
👉 Architectural and performance nuances of leading vector databases in the market.
👉 Strategies to ensure seamless deployment, security, and operational excellence with vector databases.
Go ahead and save your seat here.
And, if you can’t make it live, don’t worry… We’ll send a replay to everyone who registers now.
Yours Truly,
Lillian Pierson
PS. If you liked this newsletter, please consider referring a friend!
Disclaimer: This email may include sponsored content or affiliate links and I may possibly earn a small commission if you purchase something after clicking the link. Thank you for supporting small business ♥️.